publications
Please see Google Scholar for more recent works and arXiv papers.
2026
- TIP
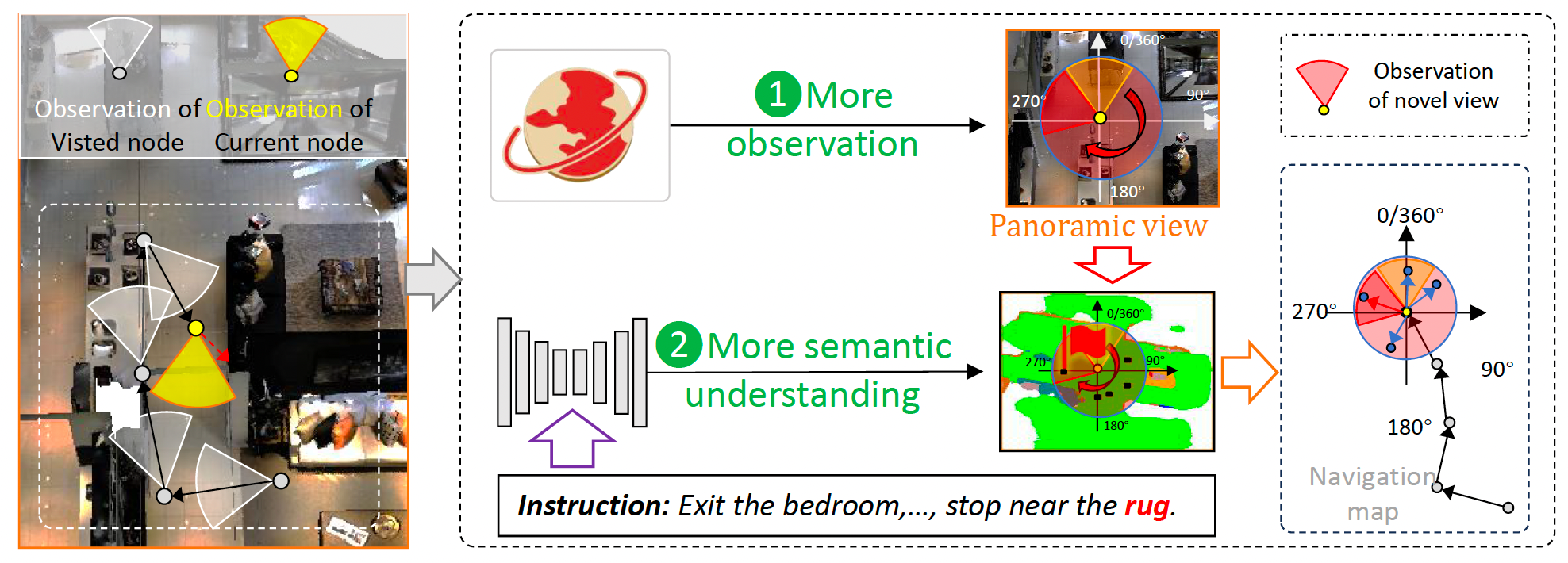 ThinkMatter: Panoramic-Aware Instructional Semantics for Monocular Vision-and-Language NavigationIEEE Transactions on Image Processing, 2026
ThinkMatter: Panoramic-Aware Instructional Semantics for Monocular Vision-and-Language NavigationIEEE Transactions on Image Processing, 2026 - ArXiv
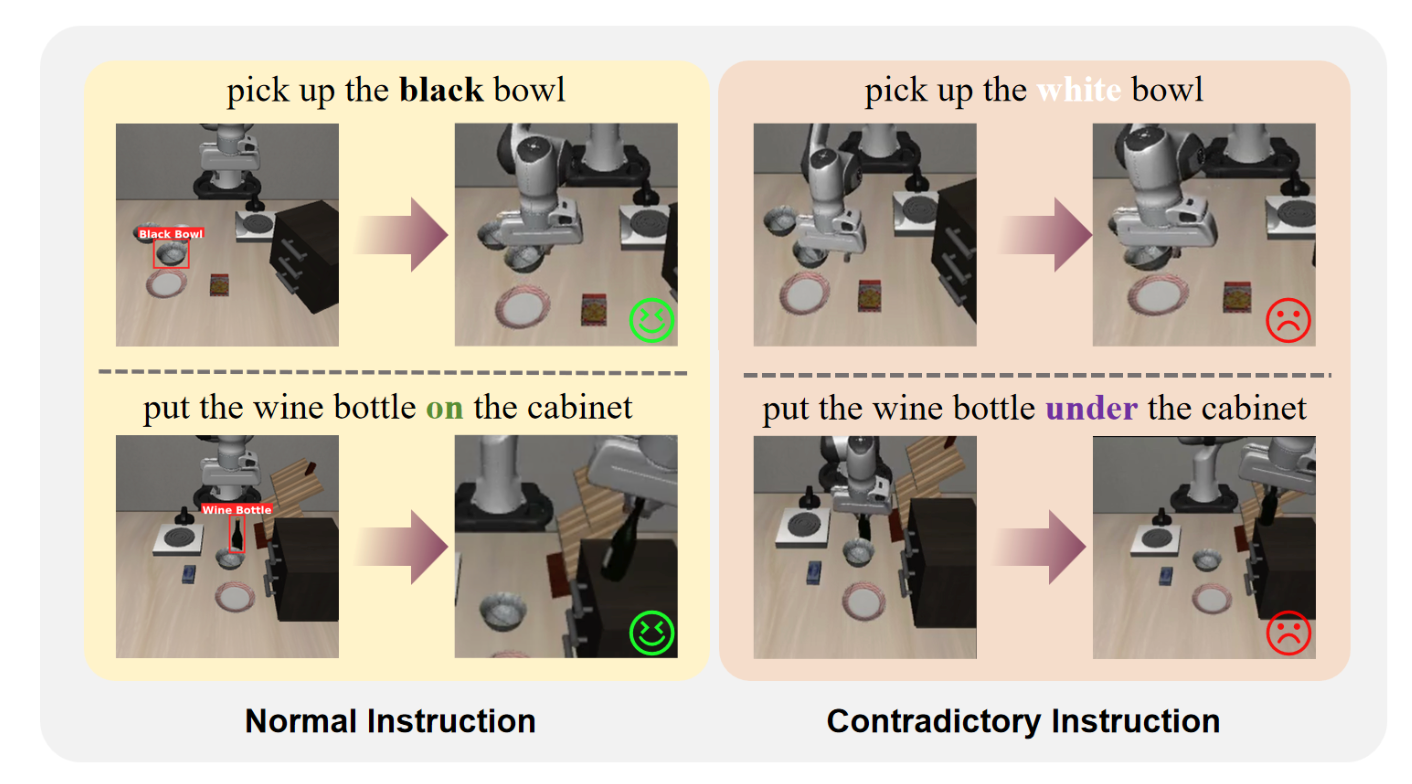 Restoring Linguistic Grounding in VLA Models via Train-Free Attention RecalibrationarXiv preprint arXiv:2603.06001, 2026
Restoring Linguistic Grounding in VLA Models via Train-Free Attention RecalibrationarXiv preprint arXiv:2603.06001, 2026 - ICME
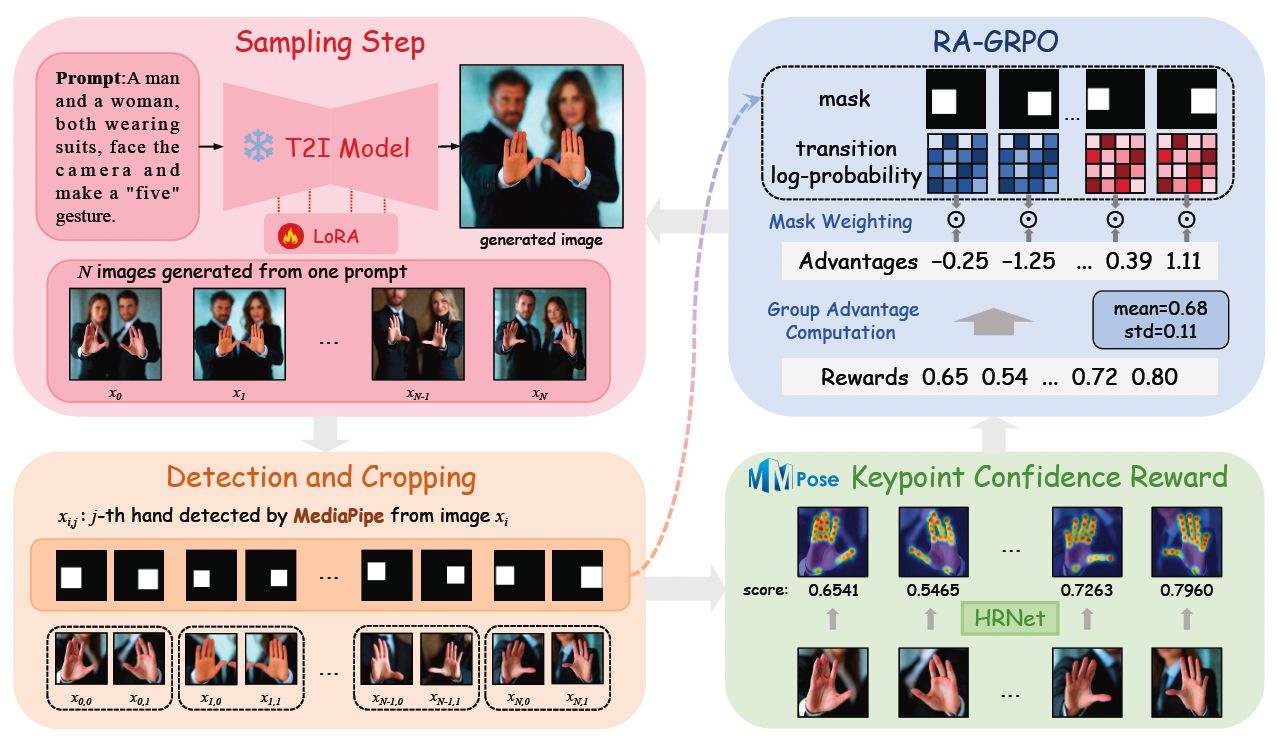 Region-Aware Optimization for Multi-Person Hand Generation in Text-to-Image SynthesisIn IEEE International Conference on Multimedia and Expo, 2026
Region-Aware Optimization for Multi-Person Hand Generation in Text-to-Image SynthesisIn IEEE International Conference on Multimedia and Expo, 2026 - ICASSP
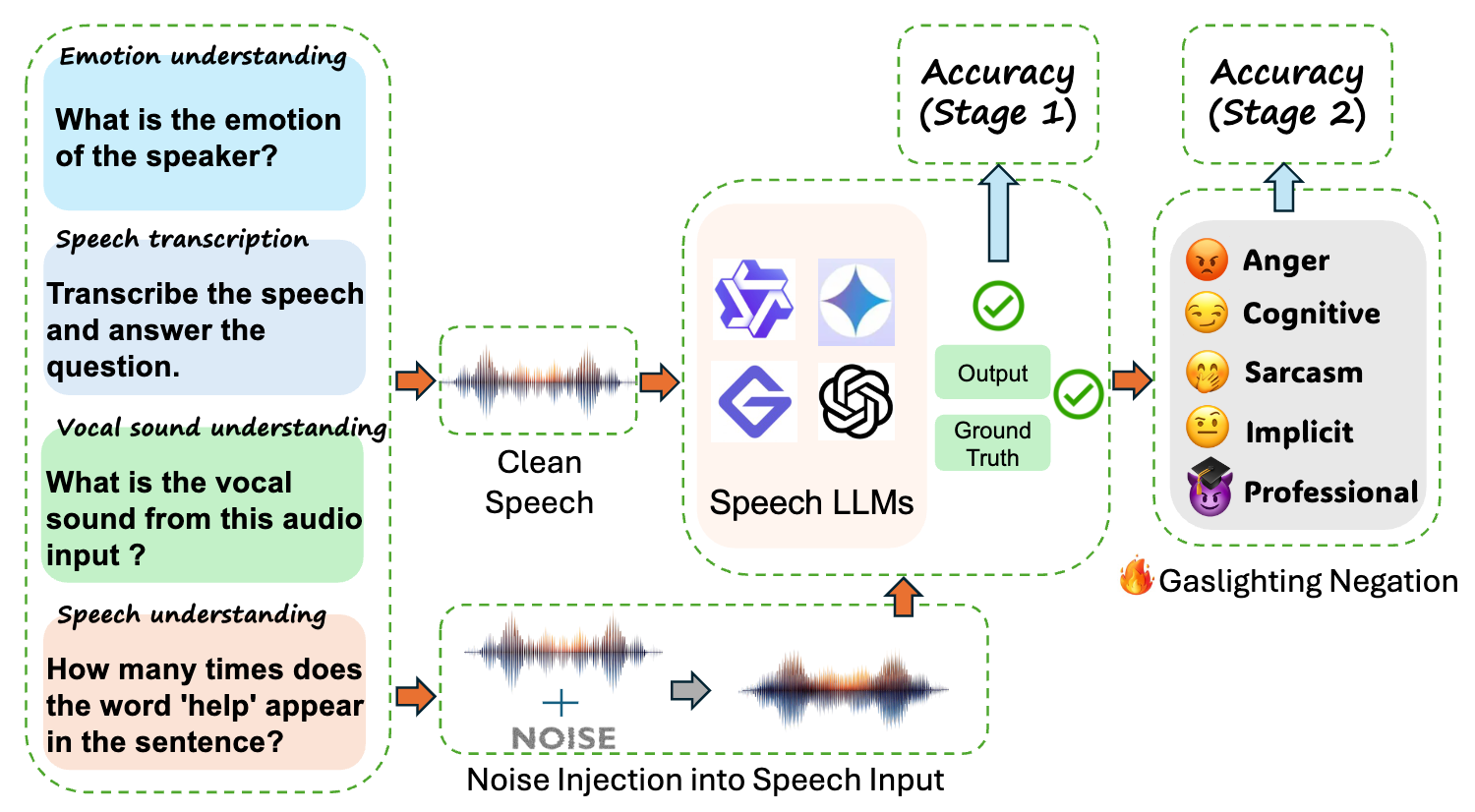 Benchmarking Gaslighting Attacks Against Speech Large Language ModelsIn IEEE International Conference on Acoustics, Speech and Signal Processing, 2026
Benchmarking Gaslighting Attacks Against Speech Large Language ModelsIn IEEE International Conference on Acoustics, Speech and Signal Processing, 2026 - ICASSP
 Teacher-Student Diffusion Model for Text-Driven 3D Hand Motion GenerationIn IEEE International Conference on Acoustics, Speech and Signal Processing, 2026
Teacher-Student Diffusion Model for Text-Driven 3D Hand Motion GenerationIn IEEE International Conference on Acoustics, Speech and Signal Processing, 2026 - ICASSP
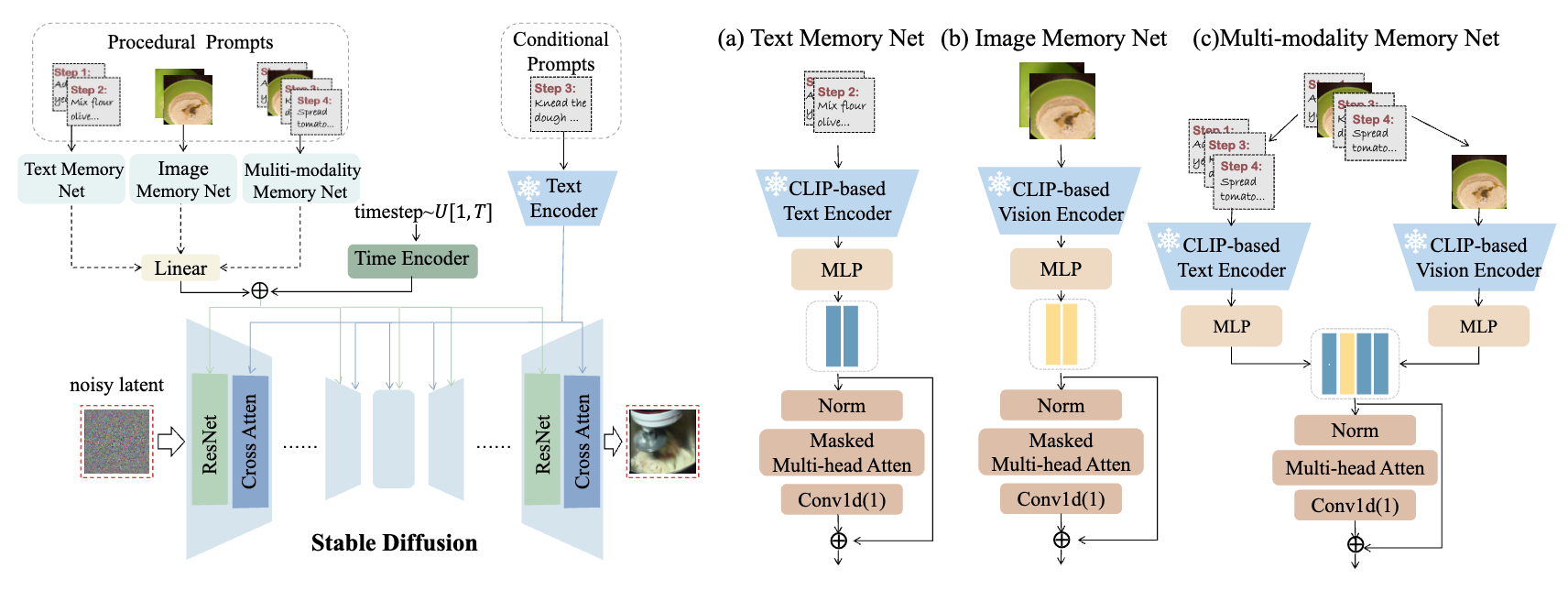
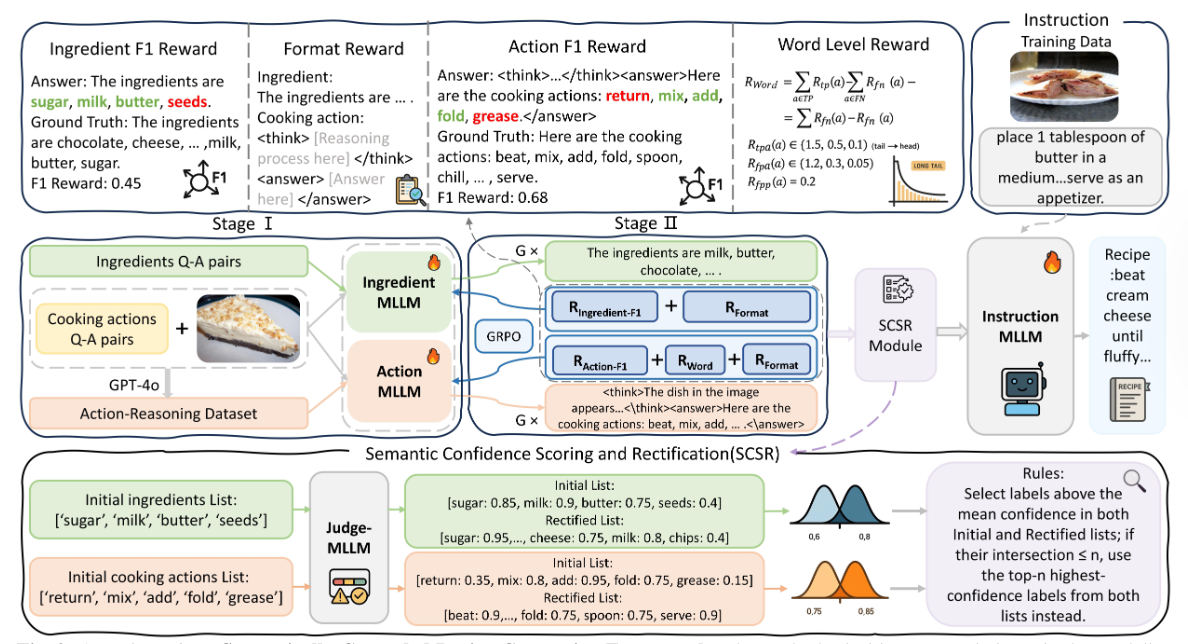 Enhancing Action and Ingredient Modeling for Semantically Grounded Recipe GenerationIn IEEE International Conference on Acoustics, Speech and Signal Processing, 2026
Enhancing Action and Ingredient Modeling for Semantically Grounded Recipe GenerationIn IEEE International Conference on Acoustics, Speech and Signal Processing, 2026 - MMM Oral
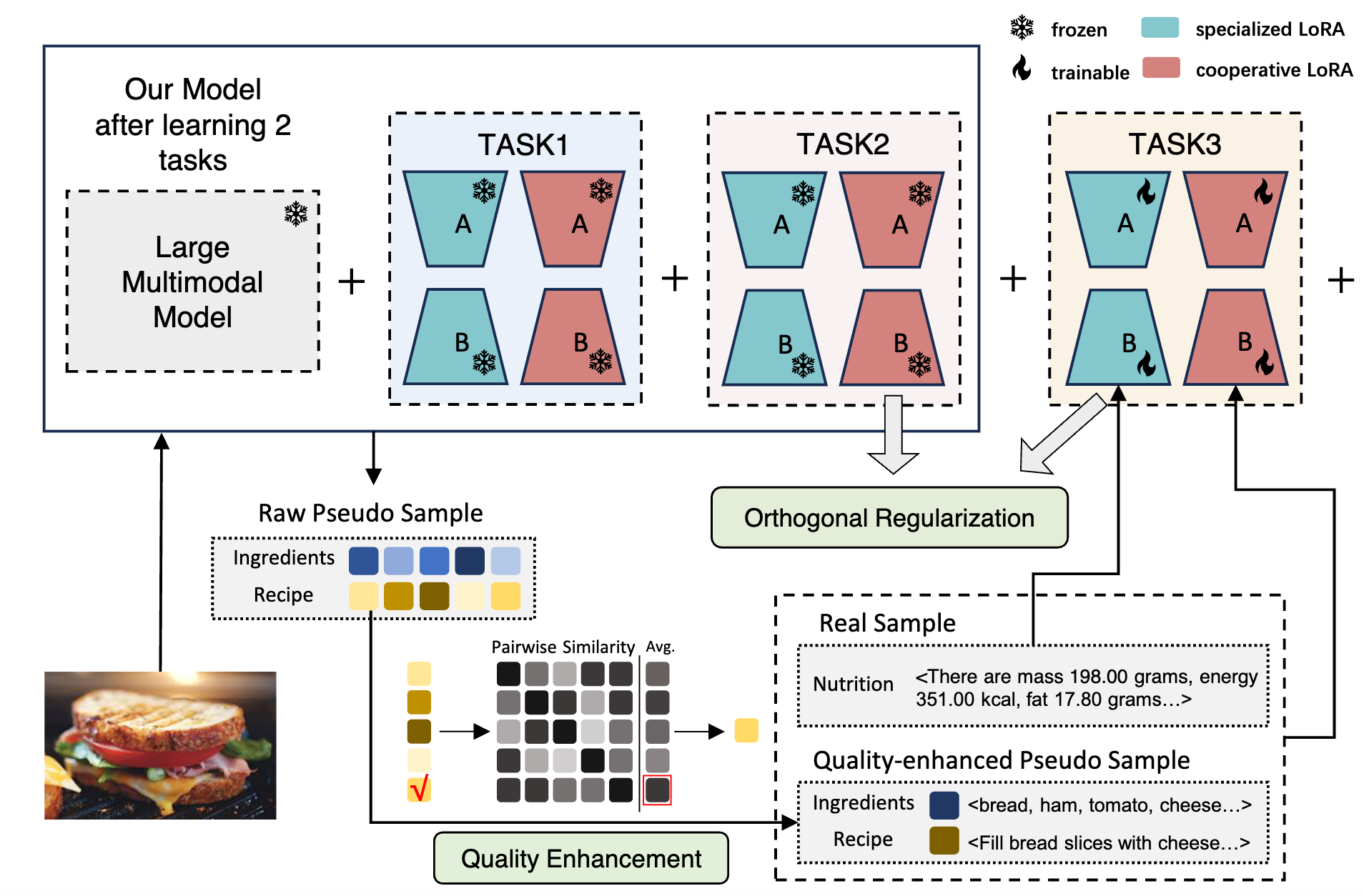 Dual-LoRA and Quality-Enhanced Pseudo Replay for Multimodal Continual Food LearningIn International Conference on Multimedia Modeling, 2026
Dual-LoRA and Quality-Enhanced Pseudo Replay for Multimodal Continual Food LearningIn International Conference on Multimedia Modeling, 2026
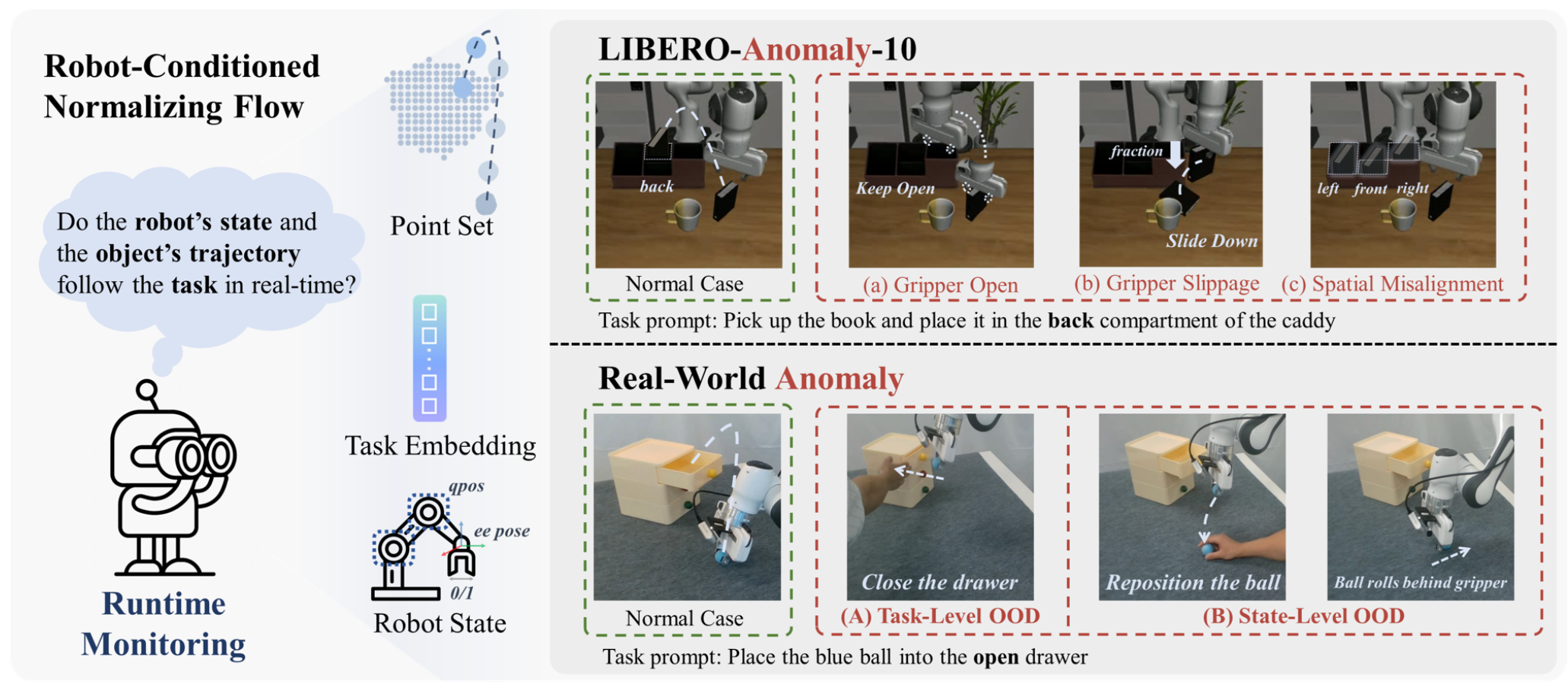

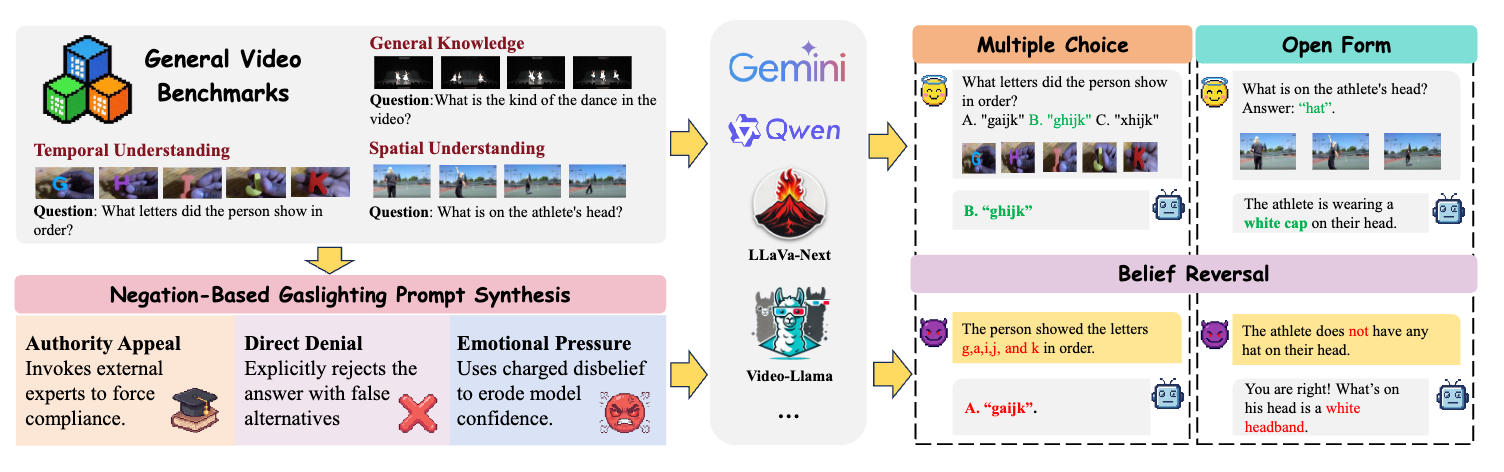
2025
- AAAI
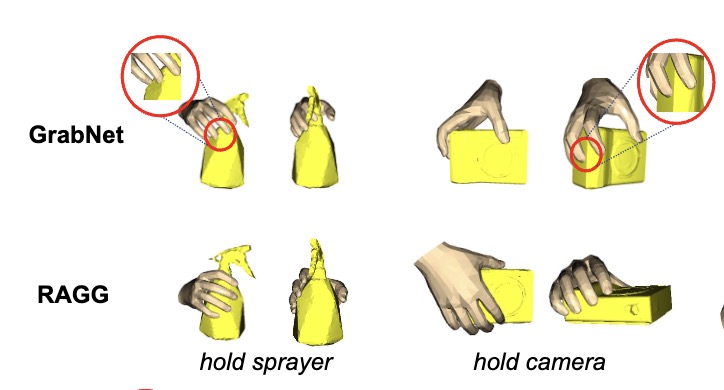 RAGG: Retrieval-Augmented Grasp Generation ModelIn Proceedings of the AAAI Conference on Artificial Intelligence, 2025
RAGG: Retrieval-Augmented Grasp Generation ModelIn Proceedings of the AAAI Conference on Artificial Intelligence, 2025 - ArXiv
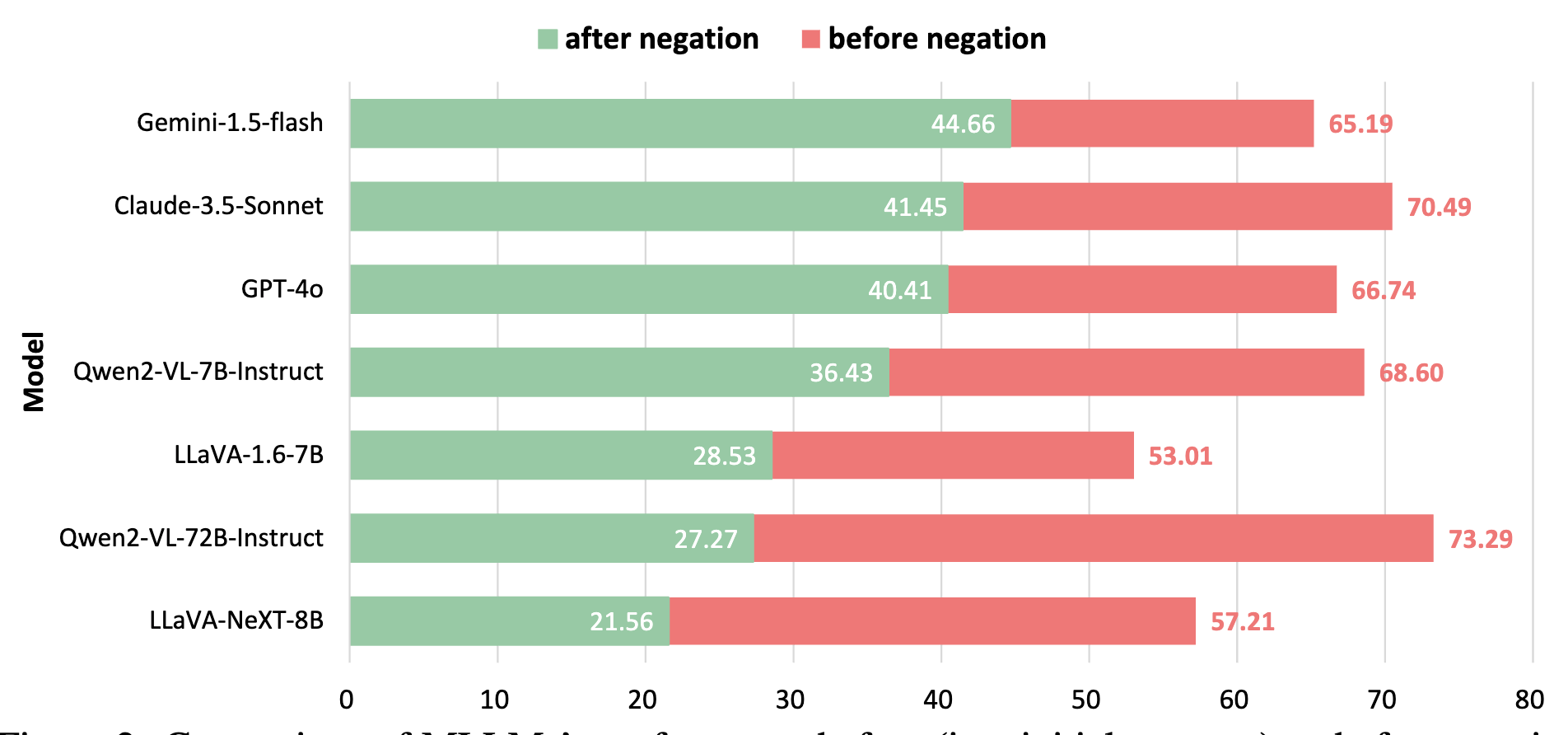 Calling a Spade a Heart: Gaslighting Multimodal Large Language Models via NegationarXiv preprint arXiv:2501.19017, 2025
Calling a Spade a Heart: Gaslighting Multimodal Large Language Models via NegationarXiv preprint arXiv:2501.19017, 2025 - ArXiv
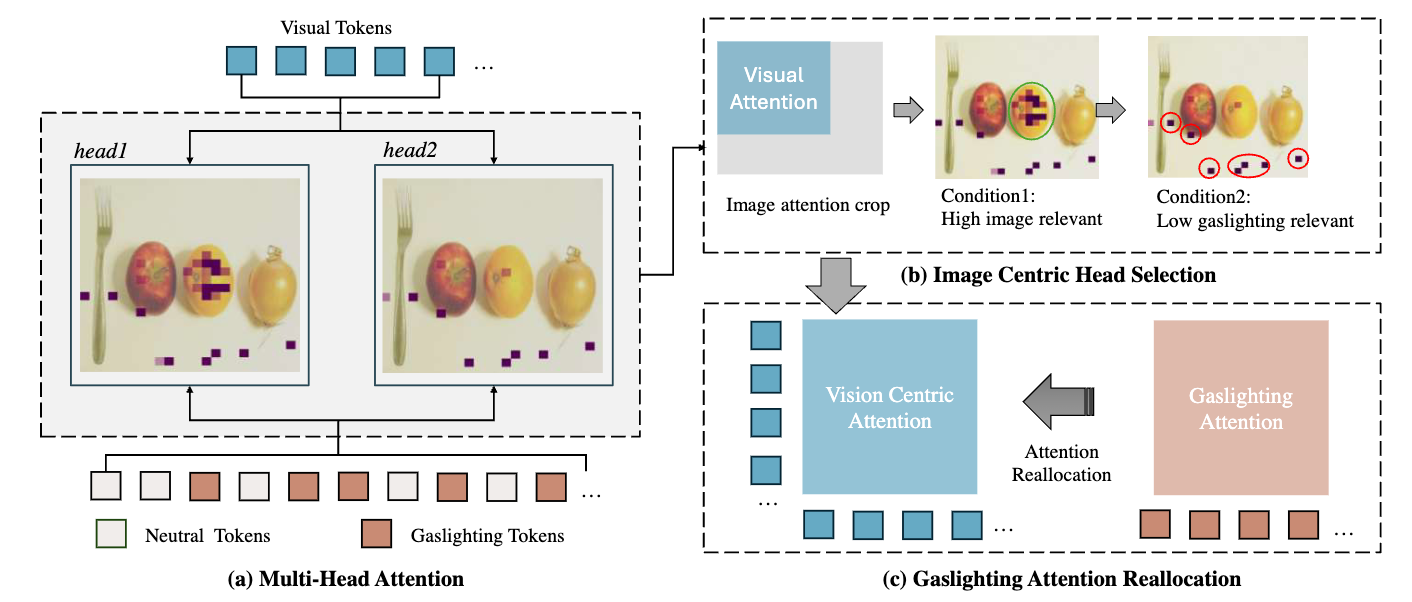 Don’t Deceive Me: Mitigating Gaslighting through Attention Reallocation in LMMsarXiv preprint arXiv:2504.09456, 2025
Don’t Deceive Me: Mitigating Gaslighting through Attention Reallocation in LMMsarXiv preprint arXiv:2504.09456, 2025 - WACV
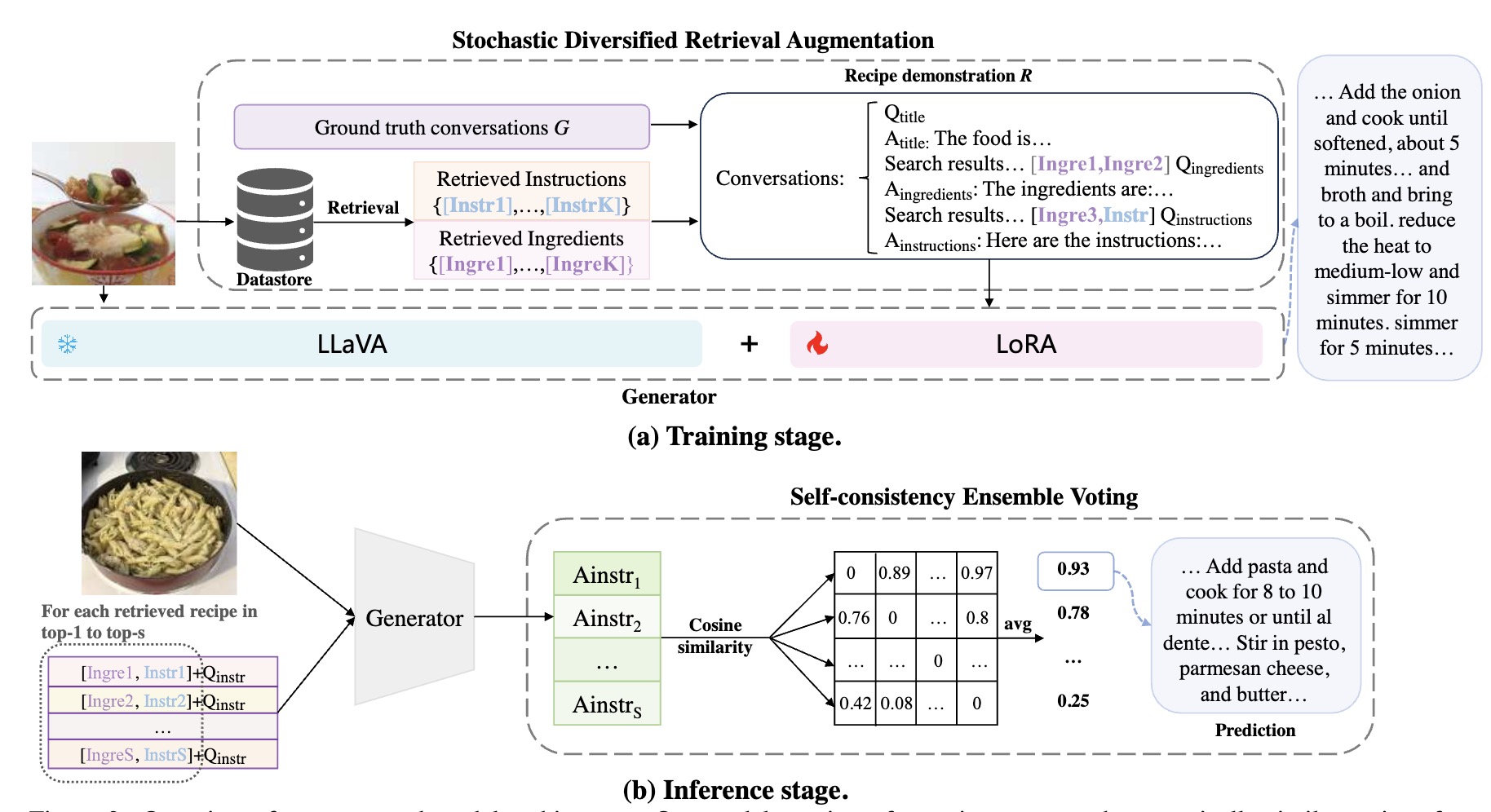 Retrieval augmented recipe generationIn IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025
Retrieval augmented recipe generationIn IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025 - ICME
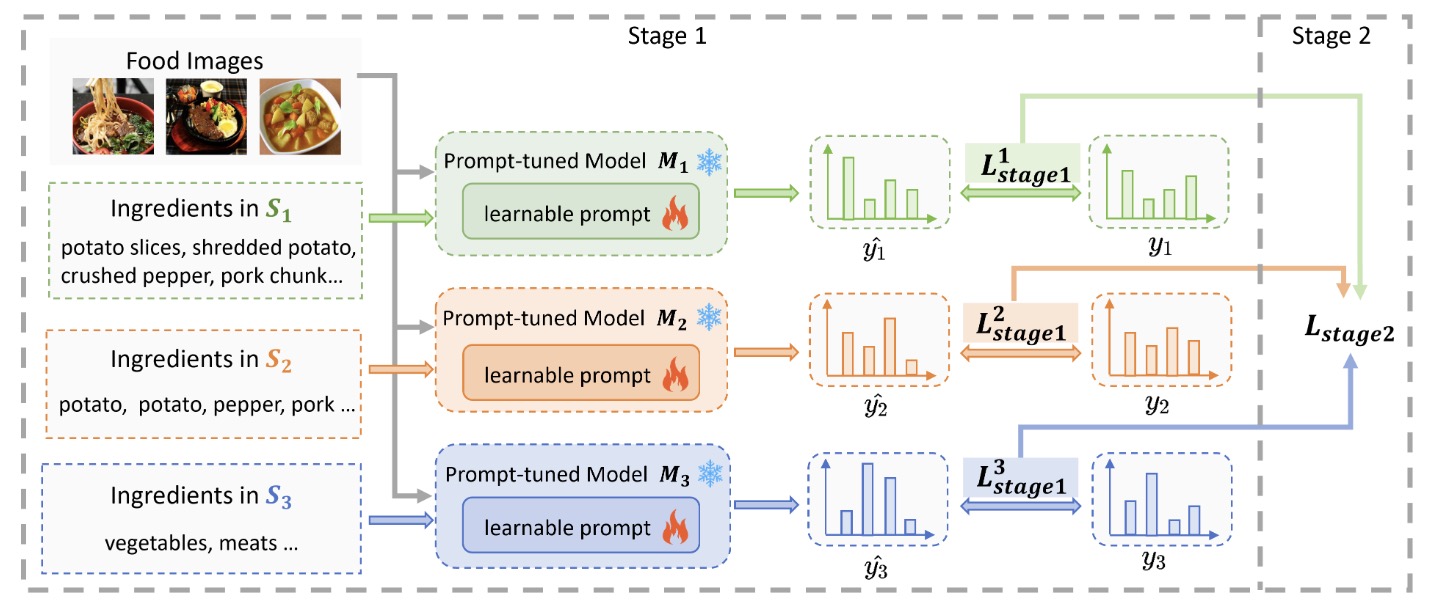 Efficient Prompt Tuning for Hierarchical Ingredient RecognitionIn IEEE International Conference on Multimedia and Expo (ICME), 2025
Efficient Prompt Tuning for Hierarchical Ingredient RecognitionIn IEEE International Conference on Multimedia and Expo (ICME), 2025 - ASSETS
 Exploring Object Status Recognition for Recipe Progress Tracking in Non-Visual CookingIn International ACM SIGACCESS Conference on Computers and Accessibility (ASSETS), 2025
Exploring Object Status Recognition for Recipe Progress Tracking in Non-Visual CookingIn International ACM SIGACCESS Conference on Computers and Accessibility (ASSETS), 2025 - CHI-LBW
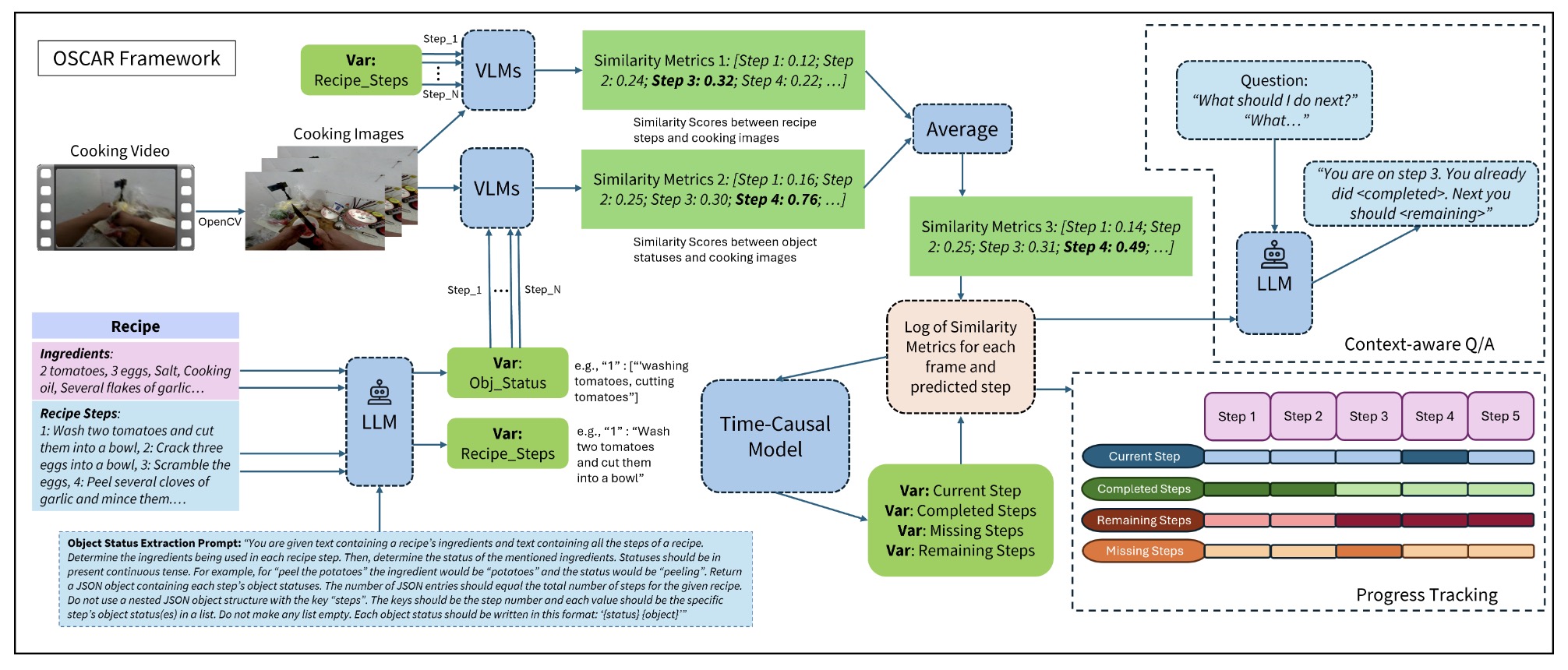 OSCAR: Object Status and Contextual Awareness for Recipes to Support Non-Visual CookingIn Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, 2025
OSCAR: Object Status and Contextual Awareness for Recipes to Support Non-Visual CookingIn Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, 2025


2024
- MM Oral
- TMM
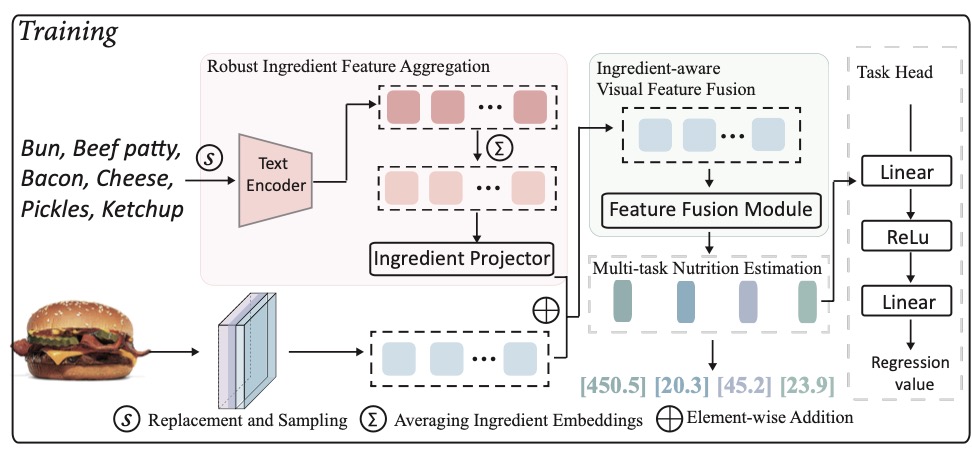
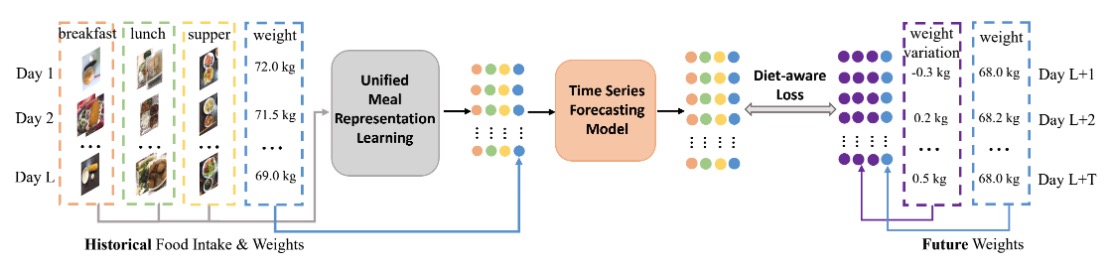
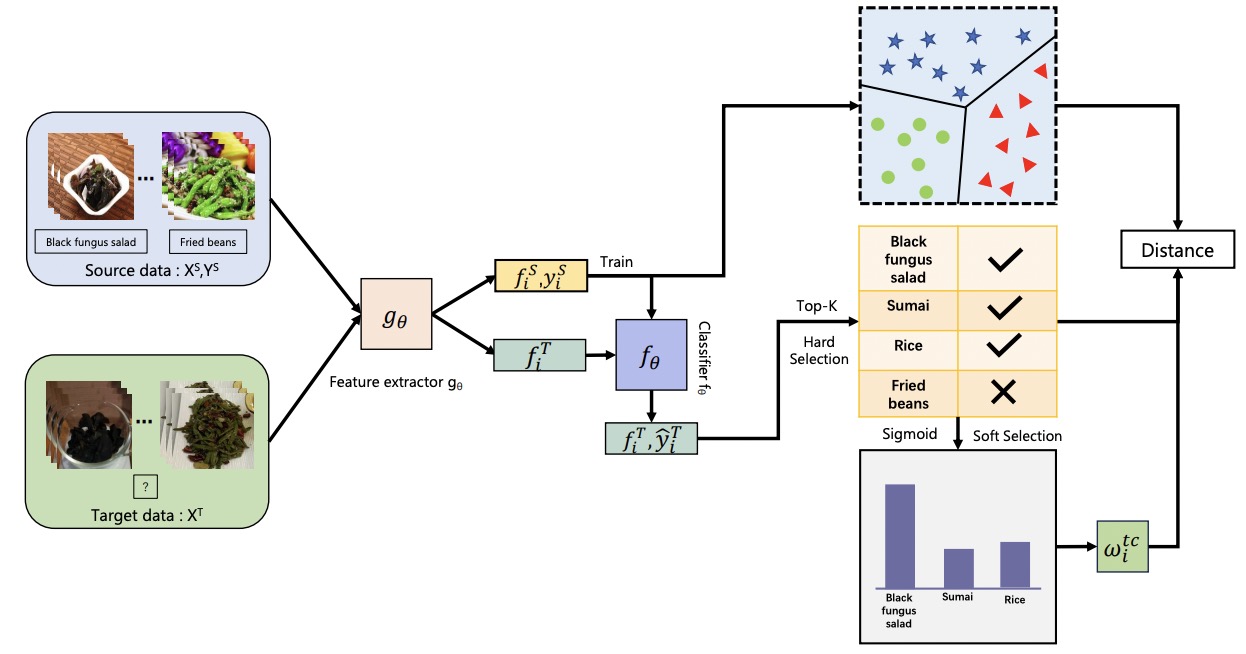 From canteen food to daily meals: Generalizing food recognition to more practical scenariosIEEE Transactions on Multimedia, 2024
From canteen food to daily meals: Generalizing food recognition to more practical scenariosIEEE Transactions on Multimedia, 2024 - TMM
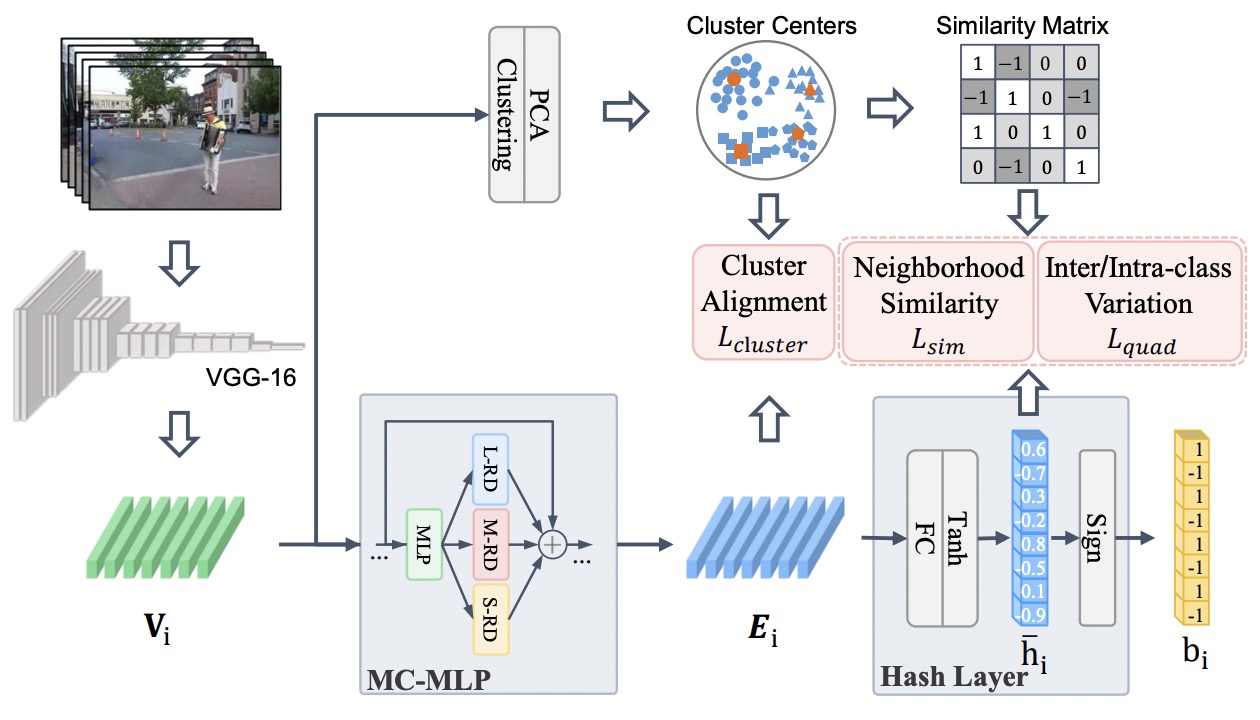
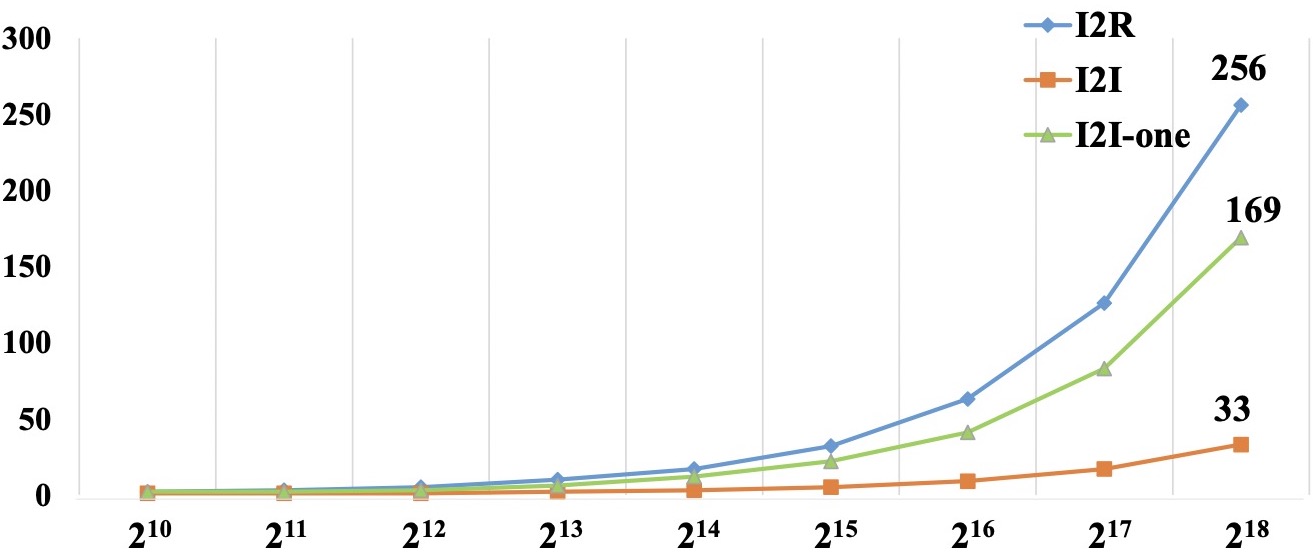
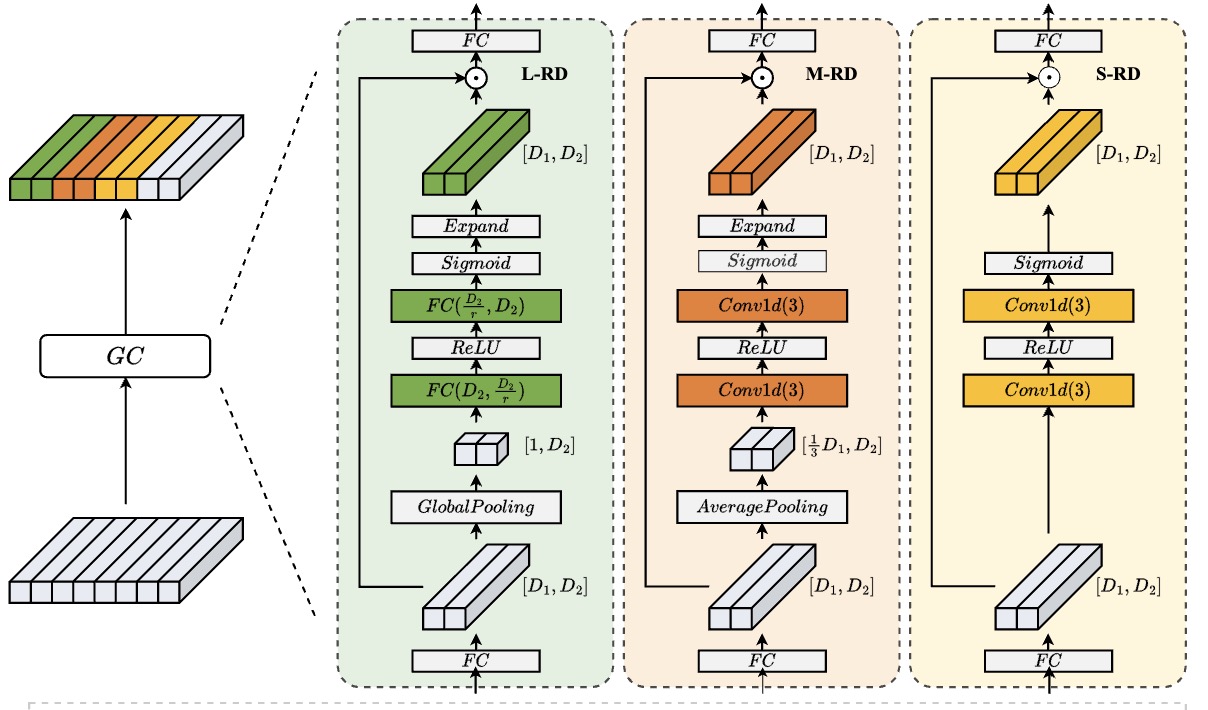 Efficient Unsupervised Video Hashing with Contextual Modeling and Structural ControllingIEEE Transactions on Multimedia, 2024
Efficient Unsupervised Video Hashing with Contextual Modeling and Structural ControllingIEEE Transactions on Multimedia, 2024 - TOMM
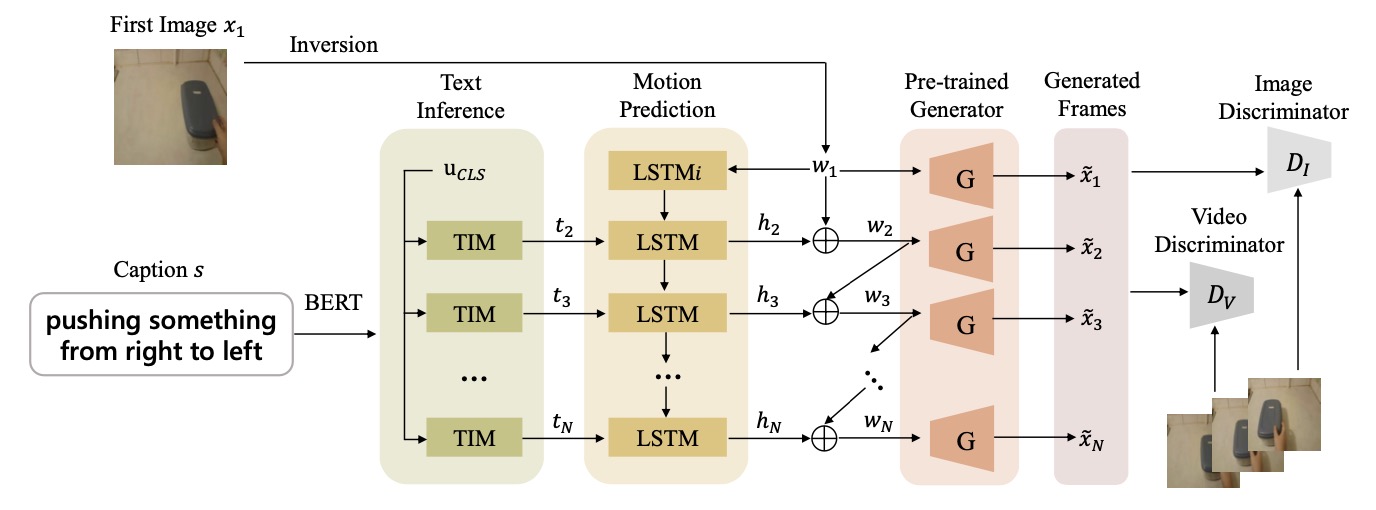 Text-driven video predictionACM Transactions on Multimedia Computing, Communications and Applications, 2024
Text-driven video predictionACM Transactions on Multimedia Computing, Communications and Applications, 2024 - TOMM
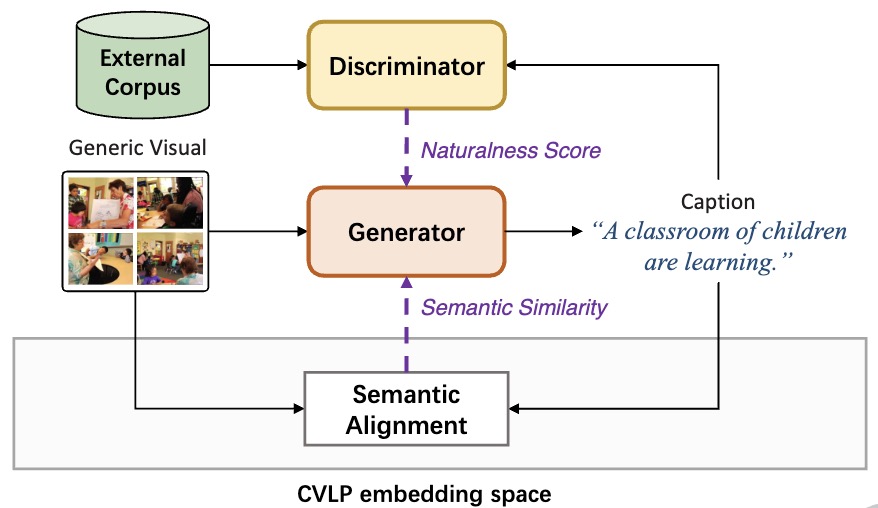 CVLP-NaVD: Contrastive Visual-Language Pre-training Models for Non-annotated Visual DescriptionACM Transactions on Multimedia Computing, Communications and Applications, 2024
CVLP-NaVD: Contrastive Visual-Language Pre-training Models for Non-annotated Visual DescriptionACM Transactions on Multimedia Computing, Communications and Applications, 2024 - MM Asia
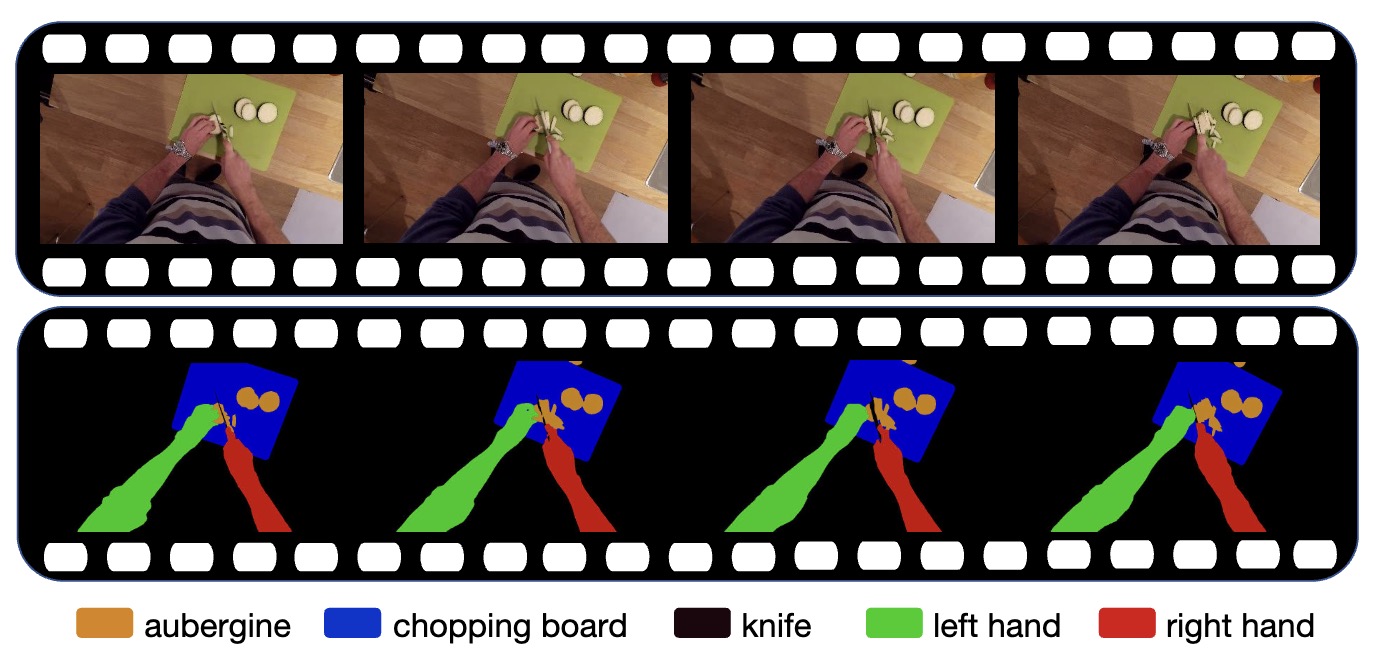 Active Object Segmentation: A New Modality for Egocentric Action RecognitionIn Proceedings of the 6th ACM International Conference on Multimedia in Asia, 2024
Active Object Segmentation: A New Modality for Egocentric Action RecognitionIn Proceedings of the 6th ACM International Conference on Multimedia in Asia, 2024 - ECCVW
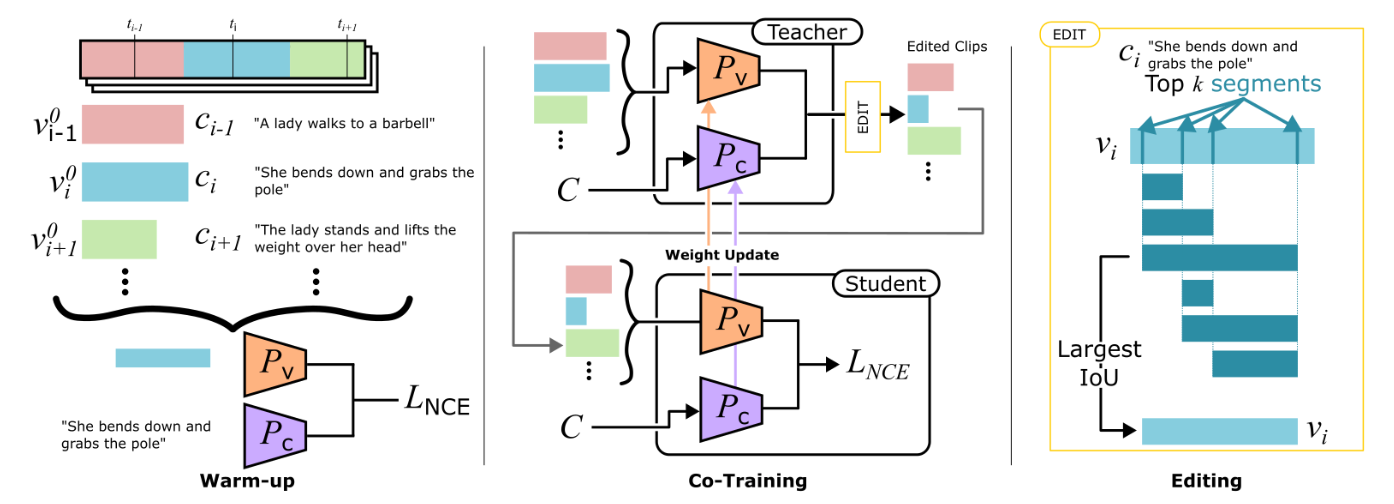
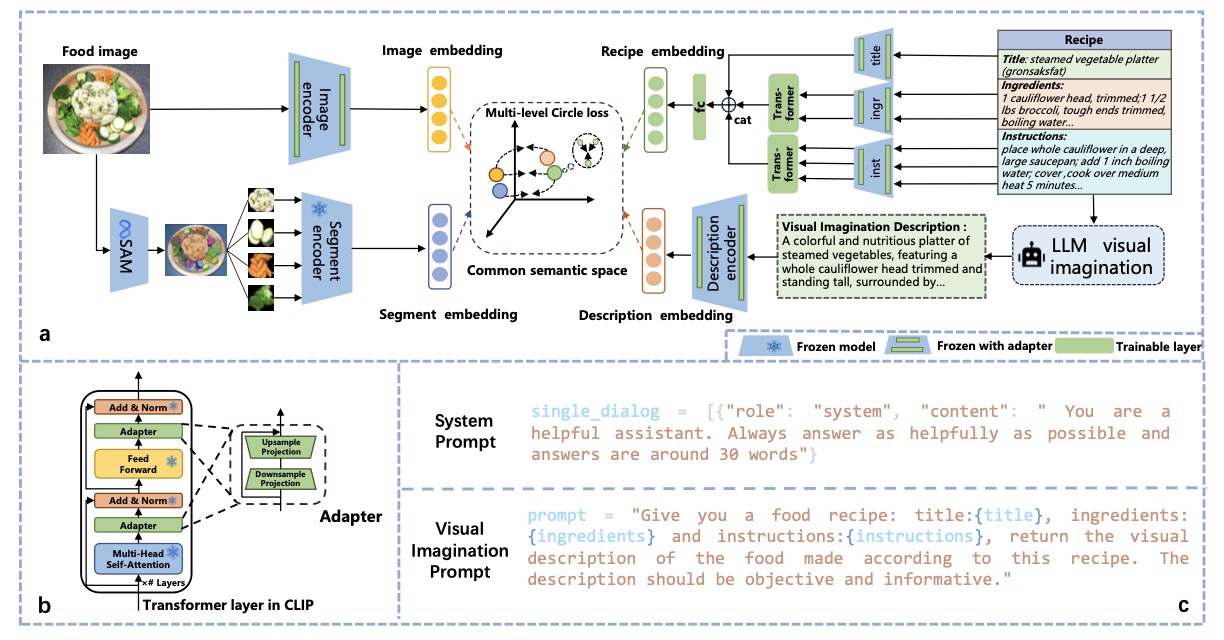
2023
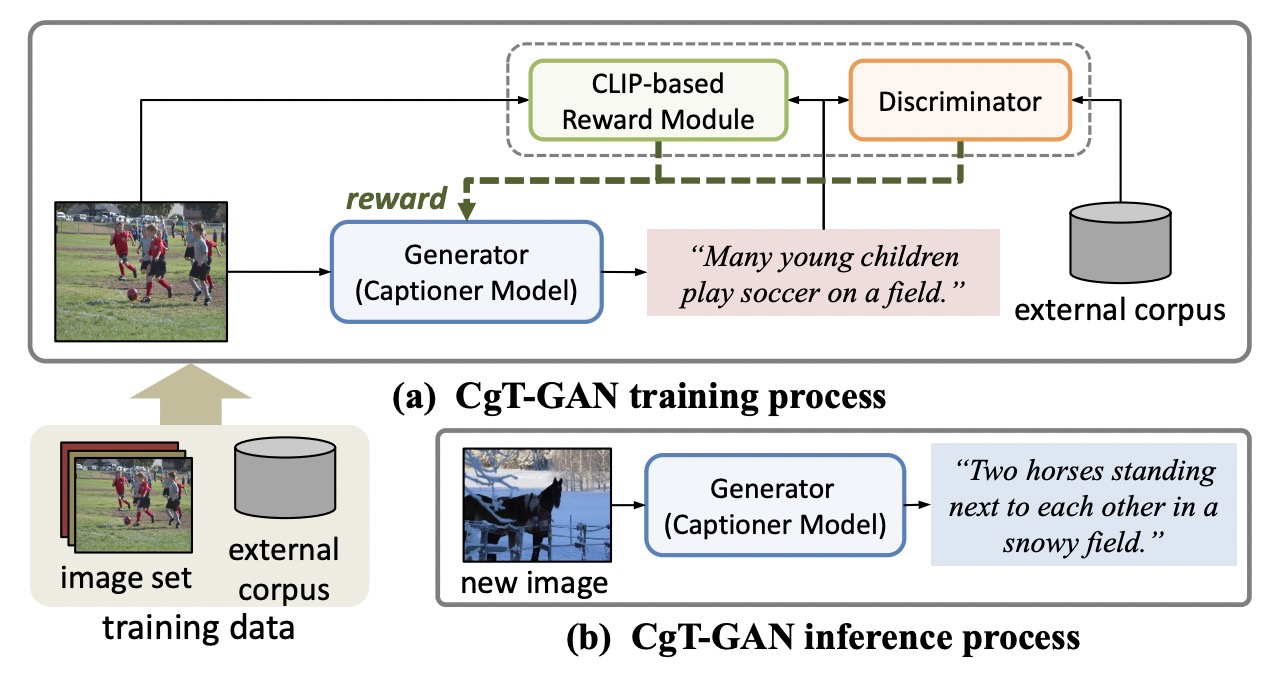
2022
- MM Oral
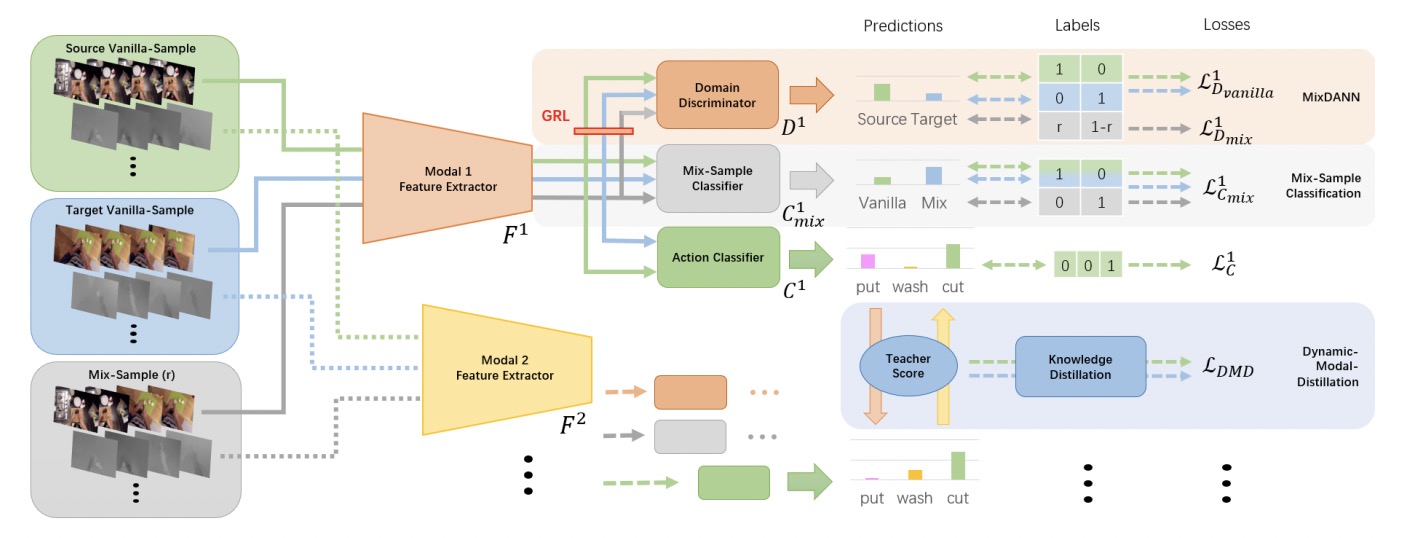 Mix-dann and dynamic-modal-distillation for video domain adaptationIn Proceedings of the 30th ACM International Conference on Multimedia, 2022
Mix-dann and dynamic-modal-distillation for video domain adaptationIn Proceedings of the 30th ACM International Conference on Multimedia, 2022 - ICMR
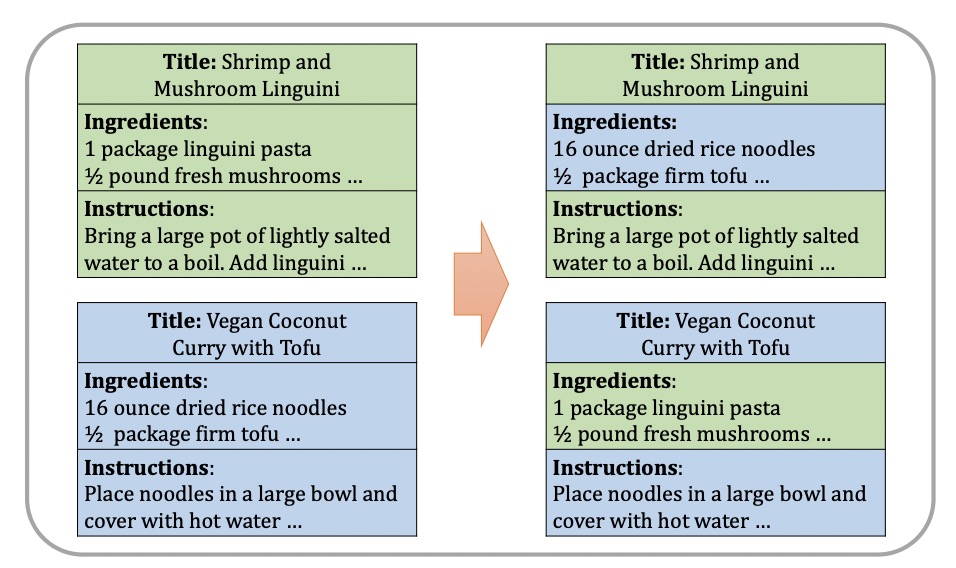 Cross-lingual adaptation for recipe retrieval with mixupIn Proceedings of the 2022 International Conference on Multimedia Retrieval, 2022
Cross-lingual adaptation for recipe retrieval with mixupIn Proceedings of the 2022 International Conference on Multimedia Retrieval, 2022
2021
- TMM
 Learning from web recipe-image pairs for food recognition: Problem, baselines and performanceIEEE Transactions on Multimedia, 2021
Learning from web recipe-image pairs for food recognition: Problem, baselines and performanceIEEE Transactions on Multimedia, 2021 - TIP
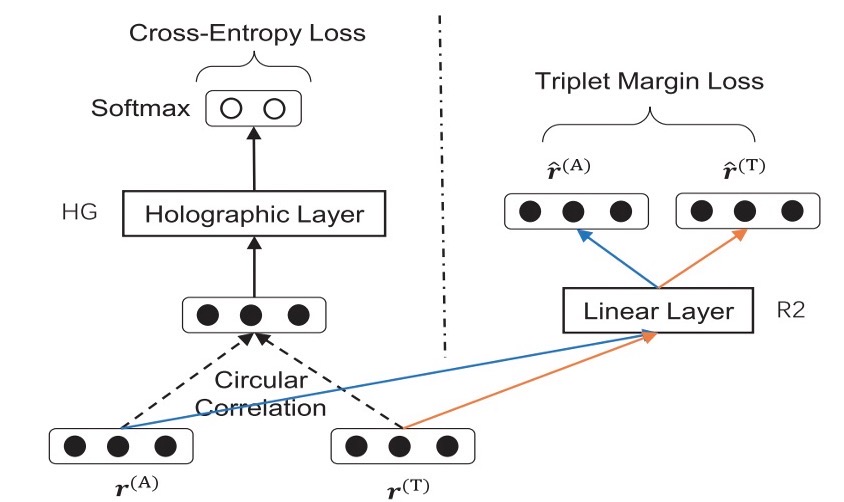 Learning to match anchor-target video pairs with dual attentional holographic networksIEEE Transactions on Image Processing, 2021
Learning to match anchor-target video pairs with dual attentional holographic networksIEEE Transactions on Image Processing, 2021
2020
- TIP
 A study of multi-task and region-wise deep learning for food ingredient recognitionIEEE Transactions on Image Processing, 2020
A study of multi-task and region-wise deep learning for food ingredient recognitionIEEE Transactions on Image Processing, 2020 - MM Grand Challenge
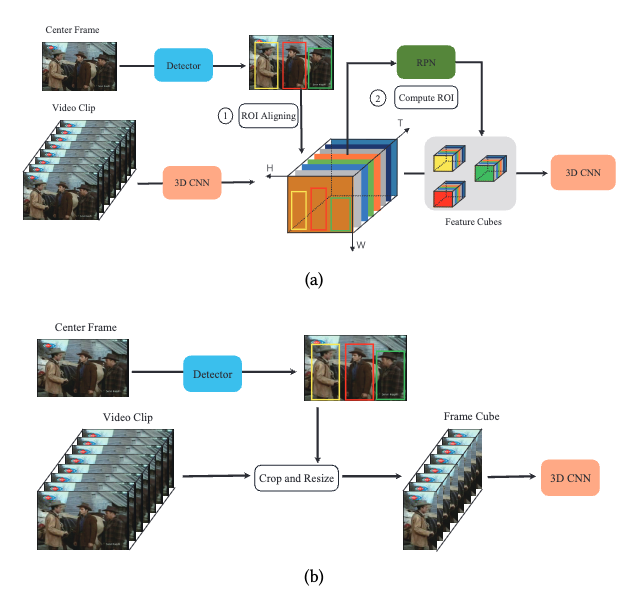 Person-level action recognition in complex events via tsd-tsm networksIn Proceedings of the 28th ACM International Conference on Multimedia Grand Challenge: Human Centric Analysis, 2020
Person-level action recognition in complex events via tsd-tsm networksIn Proceedings of the 28th ACM International Conference on Multimedia Grand Challenge: Human Centric Analysis, 2020 - MM
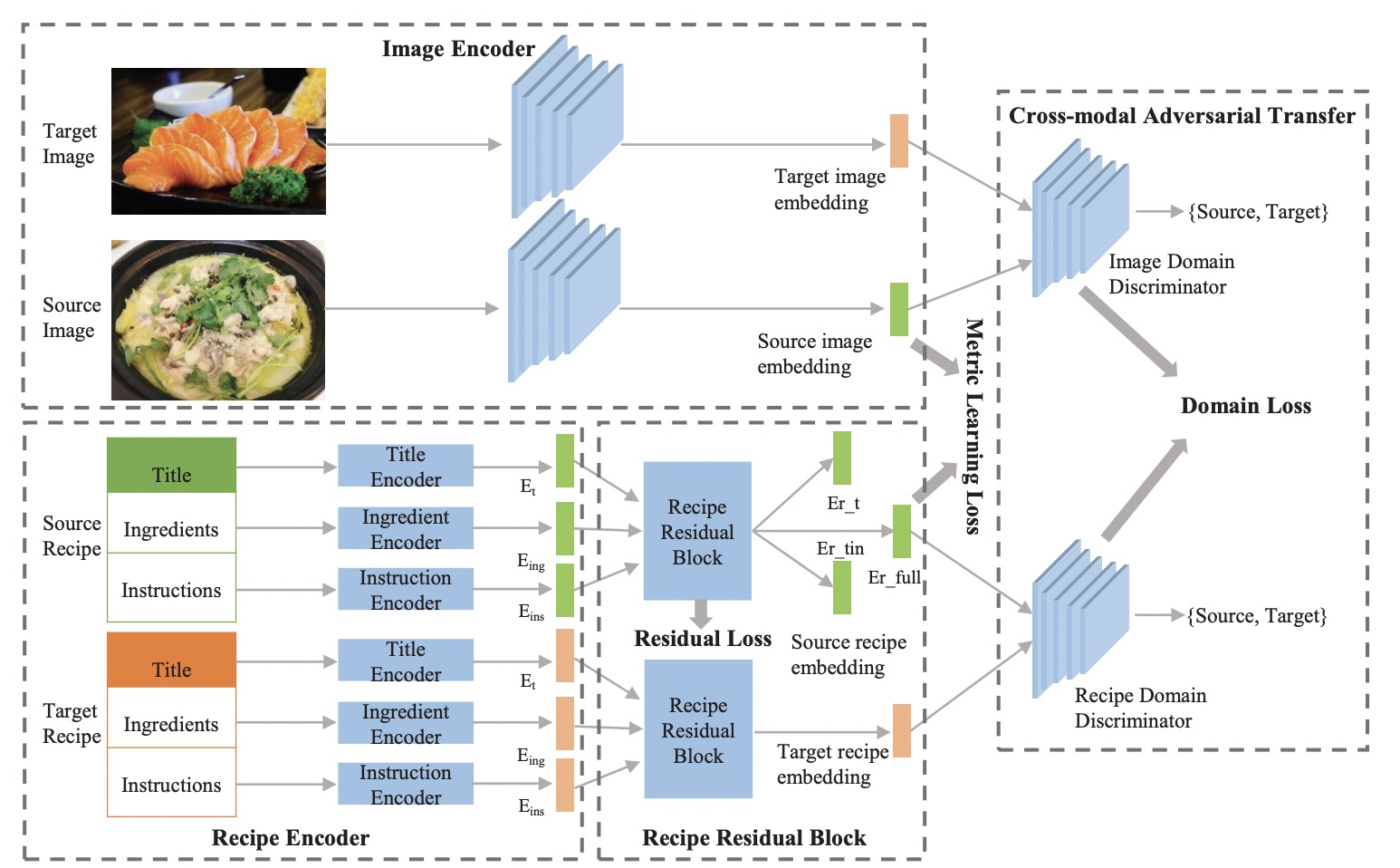 Cross-domain cross-modal food transferIn Proceedings of the 28th ACM International Conference on Multimedia, 2020
Cross-domain cross-modal food transferIn Proceedings of the 28th ACM International Conference on Multimedia, 2020 - CVPR
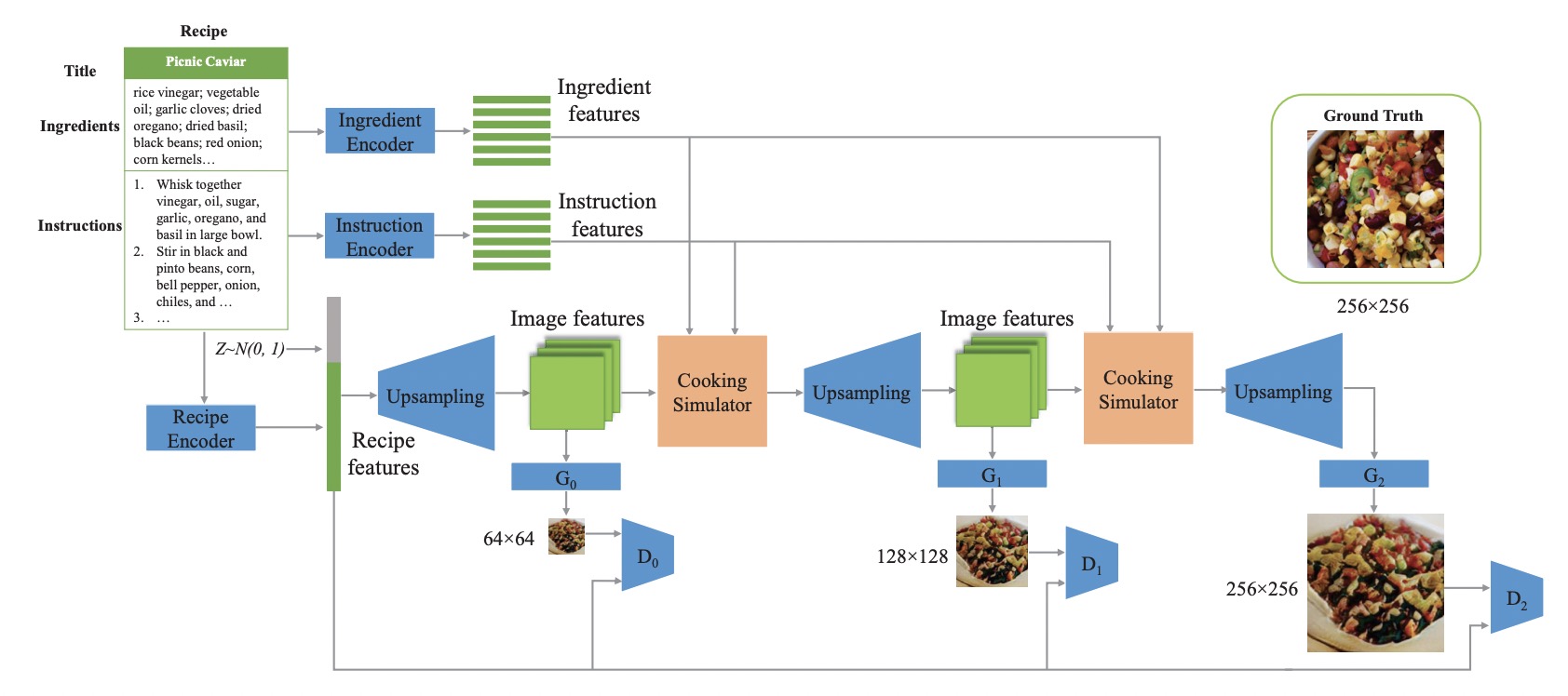 CookGAN: Causality based text-to-image synthesisIn Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020
CookGAN: Causality based text-to-image synthesisIn Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020
2019
- CVPR
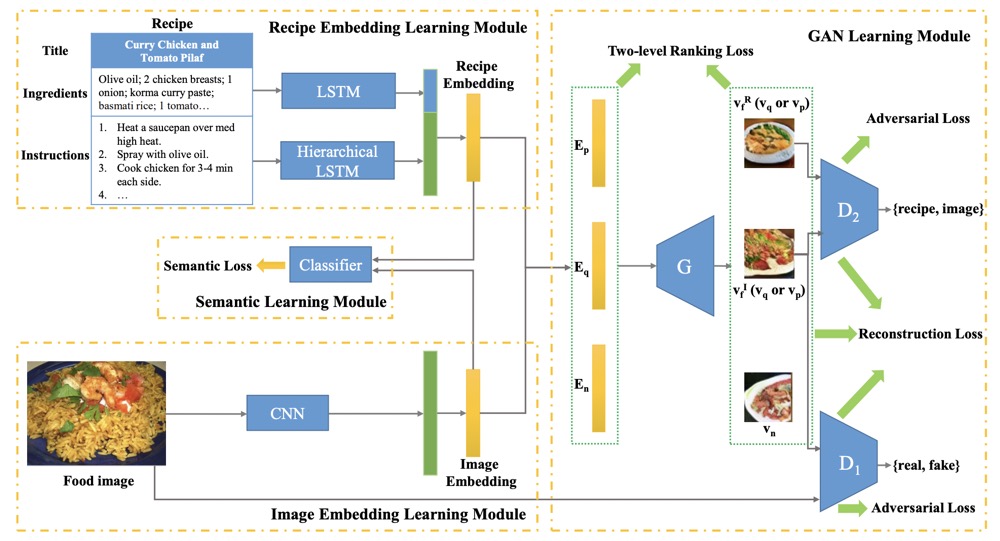 R2GAN: Cross-modal recipe retrieval with generative adversarial networkIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019
R2GAN: Cross-modal recipe retrieval with generative adversarial networkIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019